



As a software developer, managing complexity is a constant challenge. Such complexity can arise from many factors, including ever-changing business requirements, along with the need for scalability and reliability in software. Over the years, different paradigms and programming methodologies have been developed. One of them is functional programming, an approach that can significantly improve the way developers handle software complexity.
What Is Functional Programming?
Functional programming (FP) is a powerful declarative programming paradigm that can substantially enhance how developers approach problem-solving [1]. In essence, FP treats computation as the evaluation of mathematical expressions rather than as a sequence of imperative statements [2]. In this paradigm, functions are considered first-class citizens, capable of being created, stored, and modified just like any other variable. This flexibility enables high levels of abstraction, modularization, and predictability, resulting in programs that more accurately reflect the intended behavior of a system. Consequently, FP helps developers produce clear, concise, and reusable code, thereby improving the stability and maintainability of software systems [3].
Additionally, FP allows developers to build complex functionality by combining simple functions. This capacity for composition promotes code reuse and enables the creation of pipelines where data flows through a series of transformations, each handled by a separate function. By breaking problems down into smaller parts, developers can craft modular and highly testable code that is easier to debug and maintain over the long term [5].
Functional Thinking
In FP, it is crucial to distinguish between actions, calculations, and data. This way of thinking can help developers understand which parts of their code are easy to manage and which parts require more attention [1].
- Actions are operations that produce side effects, such as modifying an external variable, saving changes to a database, or making an HTTP request. Depending on when and how often they are executed, they may produce different results based on their execution context.
- Calculations are pure functions that only transform inputs into outputs without causing side effects. They can be executed at any time and as many times as needed, always producing the same result for the same inputs.
- Data represent facts about events. They encode meaning through their structure aligned with the problem domain. Data are used to perform calculations, and the results of those calculations then serve as inputs for actions.
For example, a shopping cart may involve:
- Add to cart: An action that changes the state of the shopping cart by including a new product. Running “Add to cart” multiple times or in different contexts would yield different results.
- Get total price: A calculation that takes the cart items as input to produce the total price. It is guaranteed to produce the same result for the same items.
- Cart items: Data that represent the items currently in the cart.
The following timeline diagram describes the interactions between the above aspects. Additional actions and data have been added to enhance the example.
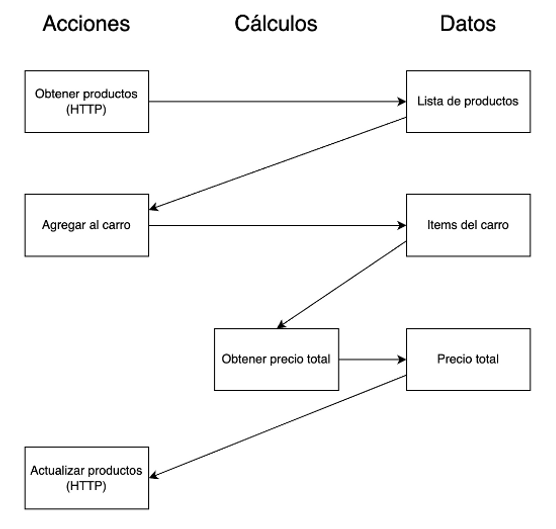
The timeline diagram is a valuable tool for visualizing the interaction between actions, calculations, and data over time. It helps make sense of complex, asynchronous, or parallel processes. Moreover, a timeline diagram can be broken down or expanded to various levels of detail depending on the problem being addressed [1].
Refactoring
Refactoring actions into calculations is a common practice in functional programming to improve testability, predictability, and code simplicity [6][7]. Let’s revisit the shopping cart example and walk through a refactoring process:
Isolation
Identify and separate parts of the code responsible for side effects from those that perform calculations. In a shopping cart, this would mean pinpointing where the code modifies global variables (like updating the total when an item is added) or interacts with external systems (like inventory checks). The goal is to clearly delineate side effects.
Example: If the cart’s total price is updated globally each time an item is added, you need to isolate this update process from the rest of the cart logic.
Extraction
Once side effects are isolated, the next step is to extract them into separate functions. This means moving code that produces side effects away from code that doesn’t, turning actions into pure functions whenever possible.
Example: From the isolated update process, extract the logic that calculates the total into its own function. Instead of one function that updates the global total and computes the new total, create a function solely to calculate the total based on the cart’s items. This function takes the cart contents as input and returns the total cost without modifying global state.
Replacement
The final step is to replace implicit dependencies and side effects in the code with explicit inputs and outputs. The goal is to make functions pure, where their output depends only on their input and not on external state.
Example: Modify the total calculation function so it no longer uses or updates any global variables. Instead, it accepts the cart contents as an argument and returns the total price. Any interaction with the cart’s state must occur outside this function, ensuring predictable behavior without side effects.
By applying these refactoring techniques to the shopping cart system, the code becomes cleaner, more modular, and easier to test. Each function has a clear purpose, side effects are managed deliberately, and predictability and maintainability are enhanced.
Conclusion
Adopting a functional programming approach isn’t just about learning a set of tools and techniques; it’s a shift in mindset toward a more structured way of thinking about software development. As actions are separated from calculations, data can be handled predictably. Additionally, tools like timeline diagrams can help design solutions visually, making it easier to produce high-quality code.
In this way, functional programming becomes a set of skills and concepts that allow developers to build and manage software complexity more effectively. This is especially true in today’s world of distributed systems and sophisticated user interfaces. Functional thinking promises not only better code quality but also an overall higher level of skill for software developers.
References
[1] E. Normand, “Grokking Simplicity: Taming Complex Software with Functional Thinking,” Simon and Schuster, 2021.
[2] K. Davis and J. Hughes, “Functional Programming,” pp. 2, 1990, doi: 10.1007/978-1-4471-3166-3
[3] C. Oliveira, “Functional Programming Techniques,” in Options and Derivatives Programming in C, Berkeley, CA: Apress, 2016, pp. 127-142.
[4] S. Höck and R. Riedl, “chemf: A purely functional chemistry toolkit,” Journal of Cheminformatics, vol. 4, no. 1, pp. 6, 2012, doi: 10.1186/1758-2946-4-38
[5] J. Hughes, “Why Functional Programming Matters,” The Computer Journal, vol. 32, no. 2, pp. 98-107, 1989, doi: 10.1093/comjnl/32.2.98
[6] S. Thompson and H. Li, “Refactoring tools for functional languages,” Journal of Functional Programming, vol. 23, no. 3, pp. 293-350, 2013, doi: 10.1017/s0956796813000117
[7] J. Gibbons, “Calculating Functional Programs,” in Lecture Notes in Computer Science: Algebraic and Coalgebraic Methods in the Mathematics of Program Construction, Berlin, Heidelberg: Springer Berlin Heidelberg, 2002, pp. 151-203.